目的
使用R统计《西游记》中:
- 共出现了多少个不同的汉字;
- 每个汉字出现了多少次;
- 出现得最频繁的汉字有哪些;
- 实现初步的可视化。
平台
所有代码在windows7系统上运行(采用windows7系统,足见我业余数据爱好者的本质。因为windows系统遇到了很多编码方式的坑,实属无奈。这里也希望自己能早日摆脱银子的限制,入mac的阵营)。
数据
《西游记》文本文件xyj.txt,4020行(段),2.2MB。
注意:这里通过链接从张宏伦博士Github上下载的数据文件的编码格式时UTF-8,在windows系统上使用R读取和写出数据要特别注意数据文件的编码格式。
实现
方案一
方案一借助stringr包对xyz.txt文件进行预处理并对每个字单独提取,然后借助dplyr包实现每个字出现次数的统计。
# 加载需要的R包
library(stringr)
library(dplyr)
# 读取数据
# 这里文件内容是中文,采用的UTF-8格式,所以对encoding进行限制
fw = readLines('data/xyj.txt', encoding = 'UTF-8') # 文件xyz.txt的4020行分别存入到了一个长度为4020的向量中
# 数据预处理和计算
# 去除向量中每个元素的开始和结尾的空格
fw.real = str_trim(fw)
# 去除向量中为空的元素
fw.real = fw.real[!fw.real == '']
# 对向量中每个字符进行拆分
fw.list = str_split(fw.real, '') # 结果是数据类型为列表
# 将数据的类型由列表转化为数据框
single = data.frame(ch = do.call('c',fw.list))
# 统计每个字出现的次数,并按次数由高到底排列
result = single %>% group_by(ch) %>% summarise(num = n()) %>% arrange(desc(num))
# 写出数据
# 在windows系统下,R写出的数据文件默认为gbk的编码方式
write.csv(result, 'data/result_r.csv', row.names = F)
# 通过参数fileEncoding,将R写出的数据文件设置为UTF-8的编码方式
write.csv(result, 'data/result_r_utf8.csv', row.names = F,fileEncoding = 'UTF-8')
这里简单举例说明向量中元素有空格(这里的空格中英文输入都可以)和值为空的元素的含义。例如,一个字符向量str1 = c(‘中国’, ‘’, ‘ 中国’, ‘ 中 国’, ‘ 中 国 ‘, ‘中 国’)。这个向量str1的第3、4和5个元素含有空格,分别含有1个、2个、3个和2个。向量str1的第2个元素为空。
方案二
方案二借助stringr包对xyz.txt文件进行预处理,借助tidytest包对每个字单独提取,然后借助dplyr包实现每个字出现次数的统计。
# 加载需要的R包
library(tidytext)
library(dplyr)
library(stringr)
# 读取数据
# 这里文件内容是中文,采用的UTF-8格式,所以对encoding进行限制
fw = readLines('data/xyj.txt', encoding = 'UTF-8') # 文件xyz.txt的4020行分别存入到了一个长度为4020的向量中
# 数据预处理和计算
# 去除向量中每个元素的开始和结尾的空格
fw.real = str_trim(fw)
# 方案二,不需要去除向量中为空的元素
# fw.real = fw.real[!fw.real == '']
# 统计每个字出现的次数,并按次数由高到底排列
result = fw_df %>%
unnest_tokens(ch, text, token = 'characters') %>% group_by(ch) %>% summarise(num = n()) %>% arrange(desc(num))
# 写出数据
# 在windows系统下,R写出的数据文件默认为gbk的编码方式
write.csv(result, 'data/result_r.csv', row.names = F)
# 通过参数fileEncoding,将R写出的数据文件设置为UTF-8的编码方式
write.csv(result, 'data/result_r_utf8.csv', row.names = F,fileEncoding = 'UTF-8')
方案二使用tidytext包的unnest_tokens()函数实现了每个字的提取。unnest_tokens()函数的使用可以参考这里。
可视化
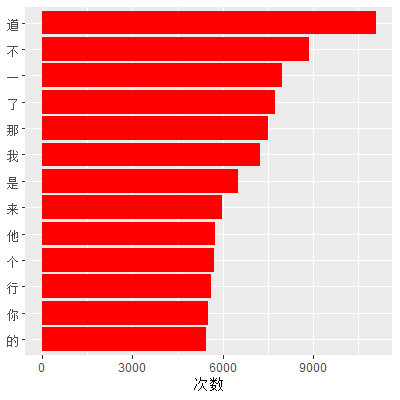
这里按照The tidy text format的步骤和方法对《西游记》中出现次数大于5000的字进行简单的可视化。其实,这里对主要用字的可视化对分析《西游记》意义并不大,更多的是学习数据可视化的方法和整个用字统计处理流程。意义不大的原因有(这里的原因主要是张宏伦博士提出的,我也十分赞同):
- 《西游记》主要用字很可能在其他文章中出现的字数也很高;
- 与英文不同,中文字本身意义并不大,更多的要结合词语语境。
使用代码:
# 找出出现次数大于5000的非标点符号字符
# 结果中result的ch列的因子水平按出现次数排序
result = result %>%
filter(!ch %in% c(',', '。', ':', '“', '”', '!') & num > 5000) %>% mutate(ch = reorder(ch, num))
# 出图
ggplot(result, aes(x = ch, y = num)) +
geom_bar(stat = "identity", fill = 'red') +
xlab(NULL) + ylab('次数') + coord_flip()
- - - - - -
参考资料